题目
原文:
Given a string s and an array of smaller strings T, design a method to search s for each small string in T.
译文:
给一个字符串S和一个字符串数组T(T中的字符串要比S短许多),设计一个算法, 在字符串S中查找T中的字符串。
解答
字符串的多模式匹配问题。
我们把S称为目标串,T中的字符串称为模式串。设目标串S的长度为m,模式串的平均长度为 n,共有k个模式串。如果我们用KMP算法(或BM算法)去处理每个模式串, 判断模式串是否在目标串中出现, 匹配一个模式串和目标串的时间为O(m+n),所以总时间复杂度为:O(k(m+n))。 一般实际应用中,目标串往往是一段文本,一篇文章,甚至是一个基因库, 而模式串则是一些较短的字符串,也就是m一般要远大于n。 这时候如果我们要匹配的模式串非常多(即k非常大),那么我们使用上述算法就会非常慢。 这也是为什么KMP或BM一般只用于单模式匹配,而不用于多模式匹配。
那么有哪些算法可以解决多模式匹配问题呢?貌似还挺多的,Trie树,AC自动机,WM算法, 后缀树等等。我们先从简单的Trie树入手来解决这个问题。
Trie树,又称为字典树,单词查找树或前缀树,是一种用于快速检索的多叉树结构。 比如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树。
Trie树可以利用字符串的公共前缀来节约存储空间,这也是为什么它被叫前缀树。
如果我们有以下单词:abc, abcd, abd, b, bcd, efg, hig, 可以构造如下Trie树: (最右边的最后一条边少了一个字母)
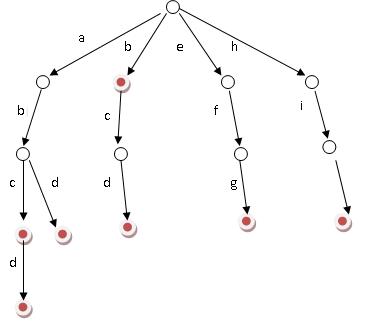
回到我们的题目,现在要在字符串S中查找T中的字符串是否出现(或查找它们出现的位置), 这要怎么和Trie扯上关系呢?
假设字符串S = “abcd”,那么它的所有后缀是:
1
2
3
4
abcd
bcd
cd
d
我们发现,如果一个串t是S的子串,那么t一定是S某个后缀的前缀。比如t = bc, 那么它是后缀bcd的前缀;又比如说t = c,那么它是后缀cd的前缀。
因此,我们只需要将字符串S的所有后缀构成一棵Trie树(后缀Trie), 然后查询模式串是否在该Trie树中出现即可。如果模式串t的长度为n, 那么我们从根结点向下匹配,可以用O(n)的时间得出t是否为S的子串。
下图是BANANAS的后缀Trie:
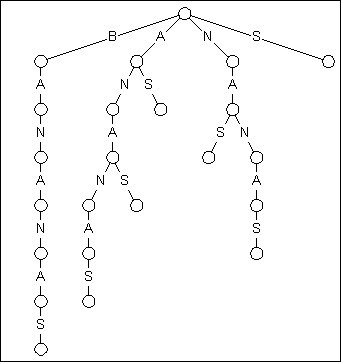
后缀Trie的查找效率很优秀,如果你要查找一个长度为n的字符串,只需要O(n)的时间, 比较次数就是字符串的长度,相当给力。 但是,构造字符串S的后缀Trie却需要O(m^2 )的时间, (m为S的长度),及O(m^2 )的空间。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
#include <iostream>
#include <cstring>
using namespace std;
class Trie{
public:
static const int MAX_N = 100 * 100;// 100为主串长度
static const int CLD_NUM = 26; // 每个结点的儿子数量(26个字母)
int size; // 用到的当前结点编号
int trie[MAX_N][CLD_NUM];
Trie(const char* s);
void insert(const char* s);
bool find(const char* s);
};
Trie::Trie(const char* s){
memset(trie[0], -1, sizeof(trie[0]));
size = 1;
while(*s){
insert(s);
++s;
}
}
void Trie::insert(const char* s){
int p = 0;
while(*s){
int i = *s - 'a';
if(-1 == trie[p][i]){
memset(trie[size], -1, sizeof(trie[size]));
trie[p][i] = size++;
}
p = trie[p][i];
++s;
}
}
bool Trie::find(const char* s){
int p = 0;
while(*s){
int i = *s - 'a';
if(-1 == trie[p][i])
return false;
p = trie[p][i];
++s;
}
return true;
}
int main(){
Trie tree("mississippi");
string patt[] = {
"is", "sip", "hi", "sis", "mississippa"
};
int n = 5;
for(int i=0; i<n; ++i)
cout<<tree.find((char*)&patt[i][0])<<endl;
return 0;
}
上述方法总的时间复杂度是:O(m^2 + kn),有没更快的算法呢?答案是肯定的。 下面就来简单介绍一下AC自动机。
AC自动机算法是解决字符串多模式匹配的一个经典方法,时间复杂度为:O(m+kn+z), 其中:m是目标串S的长度,k是模式串个数,n是模式串平均长度,z是S 中出现的模式串数量。从时间复杂度上可以看出,AC自动机比后缀Trie方法要快, m从2次方降到了1次方。
AC自动机也会先构造一棵Trie树,不同的是,它用模式串来构造Trie树。 然后遍历一次目标串S,即可求出哪些模式串出现在目标串S中。
关于AC自动机,比较好的资料是: Set Matching and Aho-Corasick Algorithm 它是 生物序列算法课的一个课件, 这个课的课件基本上都是关于字符串算法的,讲得挺好,推荐一读。
AC自动机代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
#include <iostream>
#include <queue>
#include <cstring>
using namespace std;
class ACAutomation{
public:
static const int MAX_N = 1000 * 50;
static const int CLD_NUM = 26;
int size;
int fail[MAX_N];
int tag[MAX_N];
int trie[MAX_N][CLD_NUM];
void reset();
void insert(const char* s);
void construct();
int query(const char* s);
};
void ACAutomation::reset(){
memset(trie[0], -1, sizeof(trie[0]));
tag[0] = 0;
size = 1;
}
void ACAutomation::insert(const char* s){
int p = 0;
while(*s){
int i = *s - 'a';
if(-1 == trie[p][i]){
memset(trie[size], -1, sizeof(trie[size]));
tag[size] = 0;
trie[p][i] = size++;
}
p = trie[p][i];
++s;
}
++tag[p];
}
void ACAutomation::construct(){
queue<int> q;
fail[0] = 0;
for(int i=0; i<CLD_NUM; ++i){
if(-1 != trie[0][i]){
fail[trie[0][i]] = 0;
q.push(trie[0][i]);
}
else
trie[0][i] = 0;
}
while(!q.empty()){
int u = q.front();
q.pop();
for(int i=0; i<CLD_NUM; ++i){
int &v = trie[u][i];
if(-1 != v){
q.push(v);
fail[v] = trie[fail[u]][i];
//tag[u] += tag[fail[u]];
}
else
v = trie[fail[u]][i];
}
}
}
//返回匹配的模式串个数
int ACAutomation::query(const char* s){
int p = 0, cnt = 0;
while(*s){
int i = *s - 'a';
while(-1==trie[p][i] && p!=0)//无法匹配当前字符,回退到其fail指针
p = fail[p];
p = trie[p][i];
p = p==-1 ? 0 : p;
int t = p;
while(t!=0 && tag[t]!=-1){
cnt += tag[t];
tag[t] = -1;
t = fail[t];//跳到当前字符的最大后缀,统计模式串出现个数
}
++s;
}
return cnt;
}
int main(){
ACAutomation ac;
ac.reset();
string patt[] = {
"is", "sip", "is", "sis", "mississipp"
};
int n = 5;
for(int i=0; i<n; ++i)
ac.insert((char*)&patt[i][0]);
ac.construct();
cout<<ac.query("mississippi")<<endl;
return 0;
}
对于这道题目,还有更给力的解法:Ukkonen算法, 该算法可以在线性时间和空间下构造后缀树,而且它还是在线算法! 不过它实现起来就没那么简单了,尤其是3个加速部分,分分钟把人弄晕。 上面说到的生物序列算法课件对此也有不错的讲解,同时推荐Gusfield的书: Algorithms on strings, trees, and sequences。
另外推荐一些资料:
一篇介绍后缀树的好文章:(附代码) Fast String Searching With Suffix Trees
三鲜对上文的翻译(原文找不到了,这是别人转三鲜的): 后缀树的构造方法-Ukkonen详解
下面一篇来自stackoverflow: Ukkonen’s suffix tree algorithm in plain English
上文的译文: 介绍后缀树
全书题解目录:
Cracking the coding interview–问题与解答
全书的C++代码托管在Github上:
https://github.com/Hawstein/cracking-the-coding-interview
声明:自由转载-非商用-非衍生-保持署名 | 创意共享3.0许可证,转载请注明作者及出处
出处:http://hawstein.com/2013/03/05/20.8/