题目
原文:
You have to design a database that can store terabytes of data. It should support efficient range queries. How would you do it?
译文:
让你来设计一个能存储TB级数据的数据库,而且要能支持高效的区间查询(范围查询), 你会怎么做?
解答
首先要明确,并不是所有的字段都可以做区间查询。比如对于一个员工, 性别就没有所谓的区间查询;而工资是可以做区间查询的, 例如查询工资大于a元而小于b元的员工。
我们将需要做区间查询的字段对应的字段值提取出来作为关键字构建一棵B+树, 同时保存其对应记录的索引。B+树会对关键字排序,这样我们就可以进行高效的插入, 搜索和删除等操作。我们给定一个查询区间,在B+ 树中找到对应区间开始的结点只需要O(h)的时间,其中h是树高,一般来说都很小。 叶子结点保存着记录的索引,而且是按关键字(字段值)排好序的。 当我们找到了对应区间开始的叶子结点,再依次从其下一个块中找出对应数量的记录, 直到到到查询区间右端(即最大值)为止。这一步的时间复杂度由其区间中元素数量决定。
避免使用将数据保存在内部结点的树(B+树将数据都保存在叶子结点), 这样会导致遍历树的开销过大(因为树并非常驻内存)。
讲得这么抽象,还是来张图辅助理解一下吧。
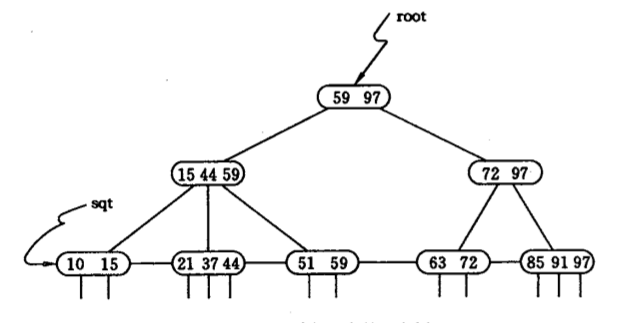
假设这棵B+树上对应的数字表示工资,单位千元。员工对应的工资数据, 其实就都保存在叶子结点上,内部结点和根结点保存的只是其子结点数据的最大值。 这里假设每个叶子结点上的工资值所在的那条记录索引并没有画出来。OK, 现在我们要查询工资大于25k小于60k的员工记录。
区间的开始值是25,我们访问根结点,发现25小于59,于是向左子结点走。 然后继续。发现25大于15且小于44,于是向其中间子结点走。 最后在叶子结点查找到第一个大于25的值是37。接下来再依次地将结点内部的其他值 (44),和它下一个叶子结点的值(51,59)对应的记录返回(不再往下查找, 因为下面的数已经大于60)。这样一来,即实现了高效的区间查询。
B+树常用于数据库和操作系统的文件系统中,你值得了解XD。
全书题解目录:
Cracking the coding interview–问题与解答
全书的C++代码托管在Github上:
https://github.com/Hawstein/cracking-the-coding-interview
声明:自由转载-非商用-非衍生-保持署名 | 创意共享3.0许可证,转载请注明作者及出处
出处:http://hawstein.com/2013/02/02/12.7/